This section deals with the use of geospatial analysis in healthcare. There is a detailed tutorial online available here
14.1 Geocoding
There are several packages avalable for obtaining geocode or longitude and latitude of location. The tmaptools package provide free geocoding using OpenStreetMap or OSM overpass API. Both ggmap and googleway access Google Maps API and will require a key and payment for access.
14.1.1 OpenStreetMap
This is a simple example to obtain the geocode of Monash Medical Centre. However, such a simple example does not always work without the full address. There are other libraries for accessing other data from OSM such as parks, restaurants etc.
library(tmaptools)mmc<-geocode_OSM ("monash medical centre, clayton")mmc
$query
[1] "monash medical centre, clayton"
$coords
x y
145.12072 -37.92088
$bbox
xmin ymin xmax ymax
145.12067 -37.92094 145.12077 -37.92083
The equivalent code in ggmap is provided below. Note that a key is required from Google Maps API.
library(ggmap)register_google(key="Your Key")#geocodegeocode ("monash medical centre, clayton")#trip#mapdist("5 stud rd dandenong","monash medical centre")
The next demonstration is the extraction of geocodes from multiple addresses embedded in a column of data within a data frame. This is more efficient compared to performing geocoding line by line. An example is provided on how to create your own icon on the leaflet document as well as taking a picture for publication.
library(dplyr)library(tidyr) #unite verb from tidyrlibrary(readr)library(tmaptools)library(leaflet)library(sf)clinic<-read_csv("./Data-Use/TIA_clinics.csv")
Rows: 25 Columns: 11
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (10): City, Country, Setting, Pre-COVID-Assessment, Post-COVID-Assessmen...
dbl (1): COVID Alert Level
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
The legacy packages maptools, rgdal, and rgeos, underpinning the sp package,
which was just loaded, will retire in October 2023.
Please refer to R-spatial evolution reports for details, especially
https://r-spatial.org/r/2023/05/15/evolution4.html.
It may be desirable to make the sf package available;
package maintainers should consider adding sf to Suggests:.
The sp package is now running under evolution status 2
(status 2 uses the sf package in place of rgdal)
m
Googleway has the flexibility of easily interrogating Google Maps API for time of trip and traffic condition.
library(googleway)key="Your Key"#trip to MMC#traffic model can be optimistic, best guess, pessimisticgoogle_distance("5 stud rd dandenong","monash medical centre", key=key, departure_time=as.POSIXct("2019-12-03 08:15:00 AEST"),traffic_model ="optimistic")
14.2 Sp and sf objects
There are several methods for reading the shapefile data. Previously rgdal library was used. This approach creates files which can be described as S4 object in that there are slots for different data. The spatial feature sf approach is much easier to handle and the data can easily be subset and merged if needed. An example of conversion between sp and sf is provided.
Here, base R plot is used to illustrate the shapefile of Melbourne and after parcellation into Voronois, centred by the hospital location.
library(dismo)
Loading required package: raster
Loading required package: sp
Attaching package: 'raster'
The following object is masked from 'package:dplyr':
select
library(ggvoronoi)
rgeos version: 0.6-3, (SVN revision 696)
GEOS runtime version: 3.11.2-CAPI-1.17.2
Please note that rgeos will be retired during October 2023,
plan transition to sf or terra functions using GEOS at your earliest convenience.
See https://r-spatial.org/r/2023/05/15/evolution4.html for details.
GEOS using OverlayNG
Linking to sp version: 2.0-0
Polygon checking: TRUE
library(tidyverse)library(sf)par(mfrow=c(1,2)) #plot 2 objects in 1 rowmsclinic<-read.csv("./Data-Use/msclinic.csv") %>%filter(clinic==1, metropolitan==1)#convert to spatialpointdataframecoordinates(msclinic) <-c("lon", "lat")#proj4string(msclinic) <- CRS("+proj=longlat +datum=WGS84")proj4string(msclinic) <-CRS("+proj=longlat +ellps=GRS80 +towgs84=0,0,0,0,0,0,0 +no_defs")#create voronoi from msclinic data#msclinic object is in spmsv<-voronoi(msclinic)#create voronoi from msclinic data#object is in spmsv<-voronoi(msclinic)#subset Greater MelbourneMelb<-st_read("./Data-Use/GCCSA_2016_AUST.shp") %>%filter(STE_NAME16=="Victoria",GCC_NAME16=="Greater Melbourne")
Reading layer `GCCSA_2016_AUST' from data source
`C:\Users\phant\Documents\Book\Healthcare-R-Book\Data-Use\GCCSA_2016_AUST.shp'
using driver `ESRI Shapefile'
Simple feature collection with 34 features and 5 fields (with 18 geometries empty)
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 96.81694 ymin: -43.74051 xmax: 167.998 ymax: -9.142176
Geodetic CRS: GDA94
#transform sf to sp objectMelb<-as(Melb,Class="Spatial")plot(Melb)#voronoi bound by greater melbournevor <- dismo::voronoi(msclinic, ext=extent(Melb))#intersect is present in base R, dplyr, raster, lubridate etcr <- raster::intersect(vor, Melb)#r<-intersect(msv,gccsa_fsp)#msclinic$hospital<-as.character(msclinic$hospital)plot(r, col=rainbow(length(r)), lwd=3)
#sp back to sf#error with epsg conversion backmsclinic_sf<-st_as_sf(msclinic,crs=4283)
Warning: st_centroid assumes attributes are constant over geometries
Com <-bind_rows(ComPoly, ComPoint)st_crs(Com)
Coordinate Reference System:
User input: EPSG:4326
wkt:
GEOGCRS["WGS 84",
ENSEMBLE["World Geodetic System 1984 ensemble",
MEMBER["World Geodetic System 1984 (Transit)"],
MEMBER["World Geodetic System 1984 (G730)"],
MEMBER["World Geodetic System 1984 (G873)"],
MEMBER["World Geodetic System 1984 (G1150)"],
MEMBER["World Geodetic System 1984 (G1674)"],
MEMBER["World Geodetic System 1984 (G1762)"],
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]],
ENSEMBLEACCURACY[2.0]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
CS[ellipsoidal,2],
AXIS["geodetic latitude (Lat)",north,
ORDER[1],
ANGLEUNIT["degree",0.0174532925199433]],
AXIS["geodetic longitude (Lon)",east,
ORDER[2],
ANGLEUNIT["degree",0.0174532925199433]],
USAGE[
SCOPE["Horizontal component of 3D system."],
AREA["World."],
BBOX[-90,-180,90,180]],
ID["EPSG",4326]]
Plot the map of community centres in Ballarat with tmap. The view argument in tmap_mode set this plotting to interactive viewing with tmap with leaflet. The leaflet library can be called directly using tmap_leaflet
#plot outline of Ballarattm_shape(Brisbane)+tm_borders()+#plot community centrestm_shape(Com) +tm_dots()
14.3 Thematic map
In the first chapter we provided thematic map examples with ggplot2, tmap and plotly.
14.3.0.1 Finland
Here we will illustrate with mapview library using open data on Finland. Mapbox is another library that can be used but that library requires registration.
pxweb 0.16.2: R tools for the PX-WEB API.
https://github.com/ropengov/pxweb
library(janitor)
Attaching package: 'janitor'
The following object is masked from 'package:raster':
crosstab
The following objects are masked from 'package:stats':
chisq.test, fisher.test
#data on Finland#https://pxnet2.stat.fi/PXWeb/pxweb/en/Kuntien_avainluvut/#Kuntien_avainluvut__2021/kuntien_avainluvut_2021_viimeisin.px/table/#tableViewLayout1/FinPop<-readxl::read_xlsx("./Data-Use/Kuntien avainluvut_20210704-153529.xlsx", skip =2)
New names:
• `` -> `...1`
FinPop2<-FinPop[-c(1),] #remove data for entire Finland#get shapefile for municipalitymunicipalities <-get_municipalities(year =2020, scale =4500) #sf object)
Warning: Coercing CRS to epsg:3067 (ETRS89 / TM35FIN)
Data is licensed under: Attribution 4.0 International (CC BY 4.0)
#join shapefile and population datamunicipalities2<-right_join(municipalities, FinPop2, by=c("name"="...1")) %>%rename(Pensioner=`Proportion of pensioners of the population, %, 2019`,Age65=`Share of persons aged over 64 of the population, %, 2020`) %>%na.omit()#plot map using mapviewmapview::mapview(municipalities2["Age65"],layer.name="Age65")
This example illustrates how to add arguments in mapview
Reading layer `geo_export_0dab2fcf-79b8-409a-b940-7c98778a4418' from data source `C:\Users\phant\Documents\Book\Healthcare-R-Book\Data-Use\NYsubways\geo_export_0dab2fcf-79b8-409a-b940-7c98778a4418.shp'
using driver `ESRI Shapefile'
Simple feature collection with 473 features and 5 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -74.03088 ymin: 40.57603 xmax: -73.7554 ymax: 40.90313
Geodetic CRS: WGS84(DD)
#list of NY hospitalsHosp<-c("North Shore University Hospital","Long Island Jewish Medical Centre","Staten Island University Hospital","Lennox Hill Hospital","Long Island Jewish Forest Hills","Long Island Jewish Valley Stream","Plainview Hospital","Cohen Children's Medical Center","Glen Cove Hospital","Syosset Hospital")#geocode NY hospitals and return sf objectHosp_geo<-geocode_OSM(paste0(Hosp,",","New York",",","USA"),as.sf =TRUE)
No results found for "Long Island Jewish Medical Centre,New York,USA".
No results found for "Lennox Hill Hospital,New York,USA".
#data from jama paper on variation in mortality from covidmapview(NYsf, zcol="boro_name")+mapview(NYsubline, zol="name")+#cex is the circle size default=6mapview(NYsubstation, zol="line",cex=1)+mapview(Hosp_geo, zcol="query", cex=3)
14.3.0.2 Denmark
The example shown under Data wrangling on how to extract data from pdf is now put to use to create thematic map of stroke number per region in Denmark.
library(dplyr)library(tidyverse)library(sf)library(eurostat)library(leaflet)library(mapview)library(tmaptools)#####################code to generate HospLocations.Rdaload ("./Data-Use/europeRGDK.Rda")#create data on hospitals#hosp_addresses <- c(# AarhusHospital = "aarhus university hospital, aarhus, Denmark",# AalborgHospital = "Hobrovej 18-22 9100 aalborg, Denmark",# HolstebroHospital = "Lægårdvej 12 7500 Holstebro, Holstebro, Denmark", VejleHospital="Vejle Sygehus,Beriderbakken 4, Vejle, Denmark",# EsbjergHospital="Esbjerg Sygehus, Esbjerg, Denmark",#SoenderborgHospital="Sydvang 1C 6400 Sønderborg, Denmark",#OdenseHospital="Odense Sygehus, Odense, Denmark", #RoskildeHospital="Roskilde Sygehus, Roskilde, Denmark", #BlegdamsvejHospital="Rigshospitalet blegdamsvej, 9 Blegdamsvej, København, Denmark", #GlostrupHospital="Rigshospitalet Glostrup, Glostrup, Denmark")#geocode hospitals using OpenStreetMap. This function works better with street addresses#HospLocations <- tmaptools::geocode_OSM(hosp_addresses, as.sf=TRUE)#convert data into sf object#HospLocations <- sf::st_transform(HospLocations, sf::st_crs(europeRGDK)) #CSC comprehensive stroke centre#PSC primary stroke centre#HospLocations$Center<-c("CSC", "PSC", "PSC", "PSC", "PSC", "PSC", "CSC", "PSC", "CSC", "PSC")#save HospLocations#save(HospLocations, "HospLocations.Rda")load("./Data-Use/HospLocations.Rda")##https://ec.europa.eu/eurostat/web/nuts/backgroundload("./Data-Use/euro_nuts2_sf.Rda")DKnuts2_sf<- euro_nuts2_sf%>%filter(str_detect(NUTS_ID,"^DK"))
old-style crs object detected; please recreate object with a recent sf::st_crs()
#convert pdf to csv filedk<-read.csv("./Data-Use/denmarkstrokepdf.csv")#extract only data on large regions=NUTS2dk2<-dk[c(4:8),]#clean up column X.1 containing stroke data#remove numerator before back slash then remove number before slash signdk2$strokenum<-str_replace(dk2$X.1,"[0-9]*","") %>%str_replace("/","\\") %>%as.numeric()dk2$Uoplyst<-str_replace(dk2$Uoplyst,"Sjælland","Sjælland")#merge sf file for DK nuts2 with stroke numberDKnuts2_sf2<-right_join(DKnuts2_sf,dk2,by=c("NUTS_NAME"="Uoplyst"))#add population from Statistics Denmark 2018 DKnuts2_sf2$pop<-c(589148,1822659,835024, 1313596,1220763)DKnuts2_sf2$male<-c(297679,894553,416092,657817,610358)DKnuts2_sf2$maleper<-round(with(DKnuts2_sf2,pop/male),2)#plot mapmapview(DKnuts2_sf2["strokenum"], layer.name="Stroke Number") +mapview(HospLocations, zcol="Center", layer.name="Hospital Designation")
old-style crs object detected; please recreate object with a recent sf::st_crs()
old-style crs object detected; please recreate object with a recent sf::st_crs()
14.3.1 Calculate distance to Hospital-OpenStreetMap
Determine distance from hospital to centroid of kommunes rather than the larger regions of Denmark. This can be performed with OpenStreetMap or Google Maps API.
This is data published in Jama 29/4/2020 on COVD-19 in New York. The New York borough shapefiles were obtained from New York Open Data at https://data.cityofnewyork.us/City-Government/Borough-Boundaries/tqmj-j8zm. For those wishing to evaluate other datasets, there’s lung and lip cancer data in SpatialEpi library, leukemia in DClusterm library. Key aspect of spatial regression is that neighbouring regions are similar and distant regions are less so. It uses the polyn2nb in spdep library to create the neighbourhood weight. The map of residual for the New York data does not suggest spatial association of residuals.
The Moran’s I is used to test for global spatial autocorrelation among adjacent regions in multidimensional space. Moran’s I requires calculation of neighbourhood. It is related to the number of regions and sum of all spatial weights.
14.4.1 New York COVID-19 mortality
The example below illustrate the need to look at the data. It is not possible to perform spatial regression given the small size of the areal data (4 connected boroughs); Staten Island does not have adjoining border with the others nor share subway system. An intriguing possibility is that areal data analysis at the neighbourhood level would allow a granular examination of socioeconomic effect of COVID-19 on mortality data. To plot the railway lines with tmap the argument tm_lines is required whereas the argument tm_polygons is better suited for plotting the shape file. It
library(leaflet)library(SpatialEpi)library(spdep)
Loading required package: spData
To access larger datasets in this package, install the spDataLarge
package with: `install.packages('spDataLarge',
repos='https://nowosad.github.io/drat/', type='source')`
library(spatialreg) #some of spdep moved to spatialreg
Loading required package: Matrix
Attaching package: 'Matrix'
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Attaching package: 'spatialreg'
The following objects are masked from 'package:spdep':
get.ClusterOption, get.coresOption, get.mcOption,
get.VerboseOption, get.ZeroPolicyOption, set.ClusterOption,
set.coresOption, set.mcOption, set.VerboseOption,
set.ZeroPolicyOption
The following objects are masked from 'package:raster':
area, select
The following object is masked from 'package:dplyr':
select
dfj<-data.frame(Borough=c("Bronx","Brooklyn","Manhattan","Queens","Staten Island"),Pop=c(1432132,2582830,1628701,2278906,476179),Age65=c(12.8,13.9,16.5,15.7,16.2),White=c(25.1,46.6,59.2,39.6,75.1),Hispanic=c(56.4,19.1,25.9,28.1,18.7),Afro.American=c(38.3,33.5,16.9,19.9,11.5),Asian=c(4.6,13.4,14,27.5,11),Others=c(36.8,10.4,15.4,17,5.2),Income=c(38467,61220,85066,69320,82166),Beds=c(336,214,534,144,234),COVIDtest=c(4599,2970,2844,3800,5603),COVIDhosp=c(634,400,331,560,370),COVIDdeath=c(224,181,122,200,143),COVIDdeathlab=c(173,132,91,154,117),Diabetes=c(16,27,15,22,25),Obesity=c(32,12,8,11,8),Hypertension=c(36,29,23,28,25)) %>%#reverse prevalence per 100000 to rawmutate(Age65raw=round(Age65/100*Pop,0),Bedsraw=round(Beds/100000*Pop,0),COVIDtestraw=round(COVIDtest/100000*Pop,0),COVIDhospraw=round(COVIDhosp/100000*Pop,0),COVIDdeathraw=round(COVIDdeath/100000*Pop),0)#Expectedrate<-sum(dfj$COVIDdeathraw)/sum(dfj$Pop)dfj$Expected<-with(dfj, Pop*rate )#SMR standardised mortality ratiodfj$SMR<-with(dfj, COVIDdeathraw/Expected)#NY Shape file - see this file open from above chunkNYsf<-st_read("./Data-Use/Borough_Boundaries/geo_export_7d3b2726-20d8-4aa4-a41f-24ba74eb6bc0.shp")
Reading layer `geo_export_7d3b2726-20d8-4aa4-a41f-24ba74eb6bc0' from data source `C:\Users\phant\Documents\Book\Healthcare-R-Book\Data-Use\Borough_Boundaries\geo_export_7d3b2726-20d8-4aa4-a41f-24ba74eb6bc0.shp'
using driver `ESRI Shapefile'
Simple feature collection with 5 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -74.25559 ymin: 40.49612 xmax: -73.70001 ymax: 40.91553
Geodetic CRS: WGS84(DD)
#join datasetNYsf<-left_join(NYsf, dfj,by=c("boro_name"="Borough"))#contiguity based neighbourhoodNY.nb<-poly2nb(NYsf) is.symmetric.nb(NY.nb) # TRUE
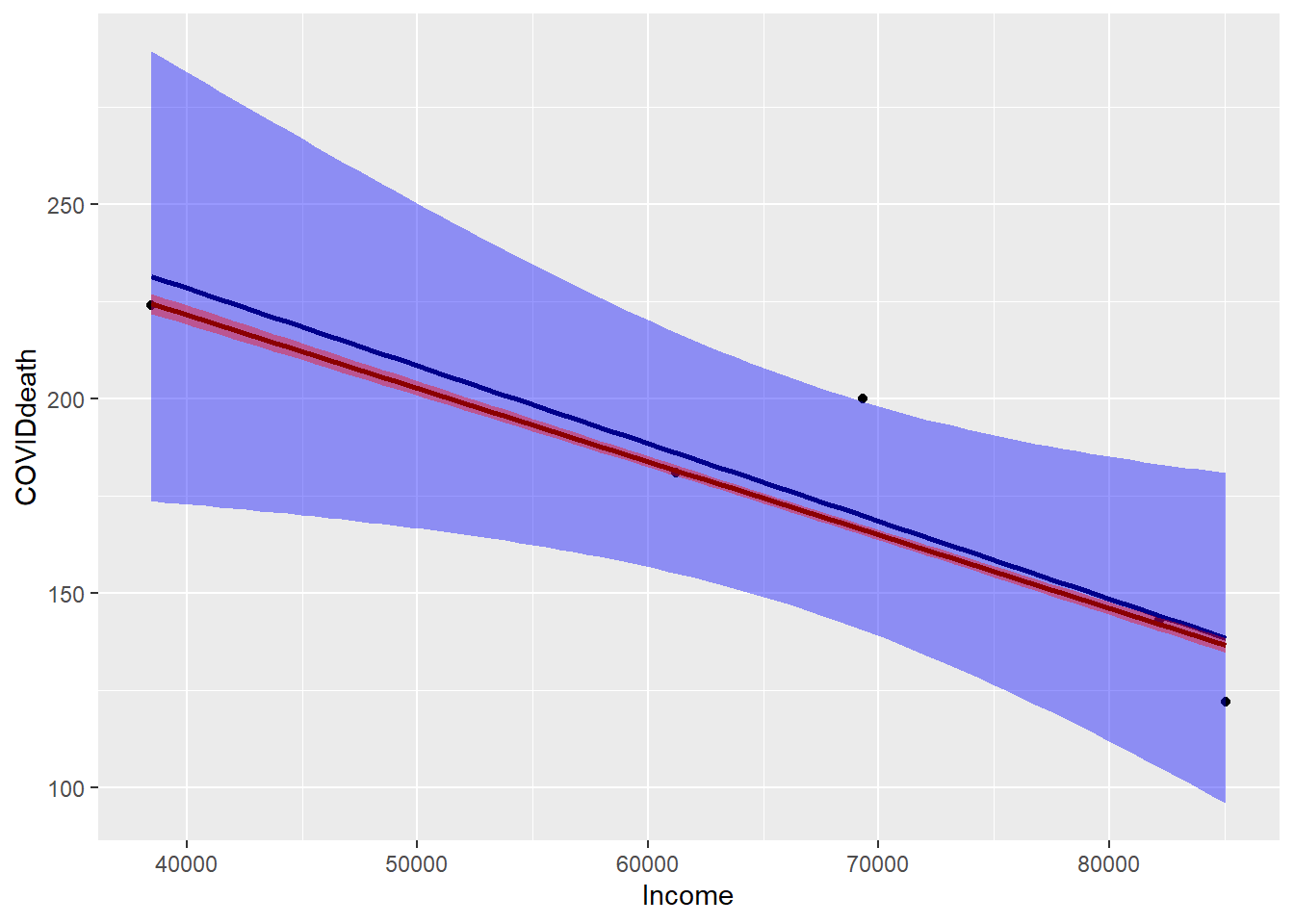
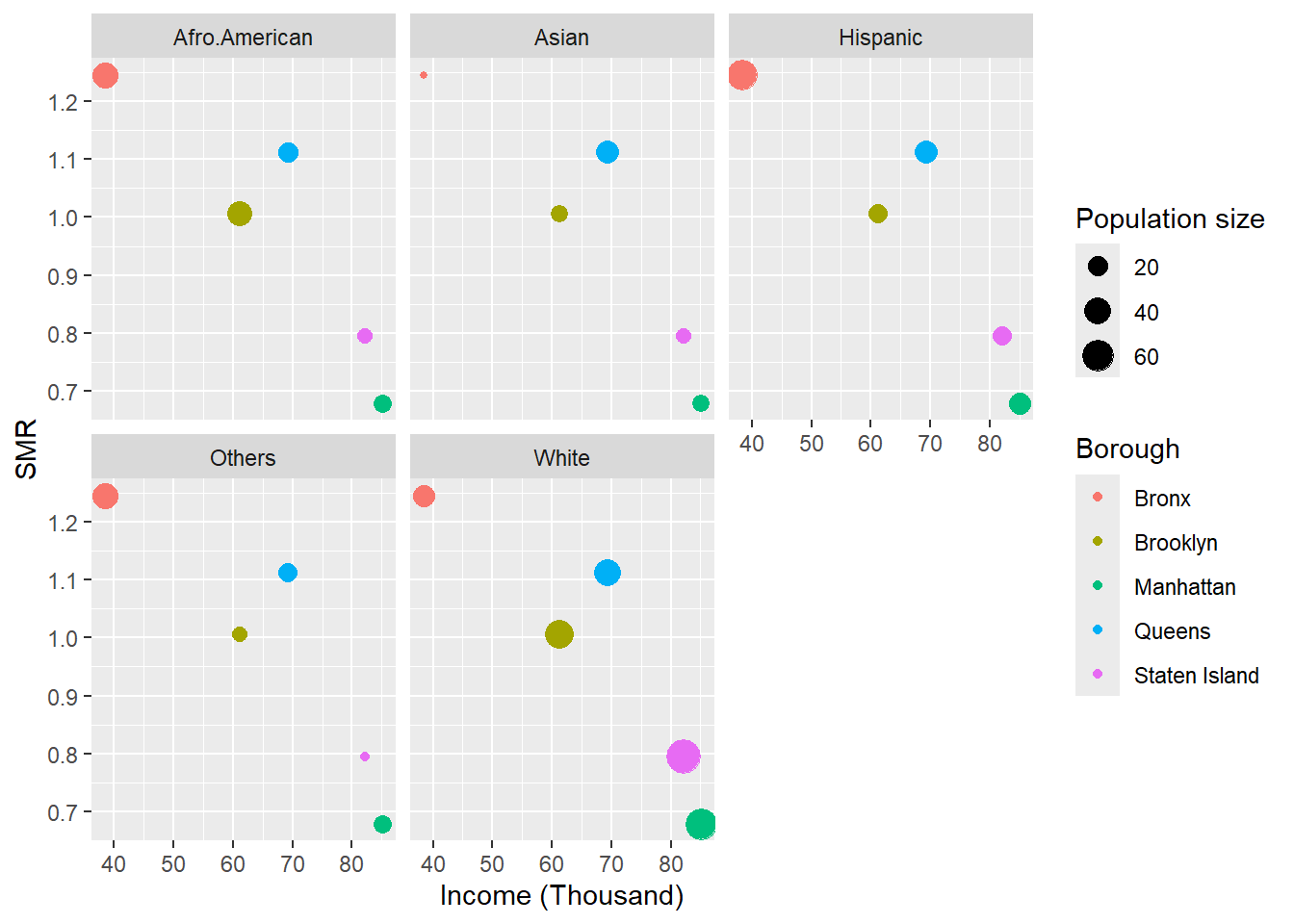
The standardized mortality ratio (ratio of mortality divided by expected value for each borough) for the boroughs were: Bronx (1.245), Brooklyn (1.006), Manhattan (0.678) Queens (1.111) and Staten Island (0.794). The Figure shows a strong relationship between standardized mortality ratio and Income (R2=0.816).
#plot regression lines linear vs robust linearggplot(data=NYsf,aes(x=Income,y=COVIDdeath)) +geom_point() +geom_smooth(method='lm',col='darkblue',fill='blue') +geom_smooth(method='rlm',col='darkred',fill='red')
`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'
Standardized mortality ratio and Income among different ethnic groups in Boroughs of New York.
Robust regression to obtain residual for plotting with thematic maps.
#robust linear modelsNYsf$resids <-rlm(COVIDdeathraw~Pop+Age65raw,data=NYsf)$res#tmap robust linear model-residual#plot using color blind argumentpar(mfrow=c(2,1))tm_shape(NYsf) +tm_polygons(col='resids',title='Residuals')
Variable(s) "resids" contains positive and negative values, so midpoint is set to 0. Set midpoint = NA to show the full spectrum of the color palette.
Variable(s) "resids" contains positive and negative values, so midpoint is set to 0. Set midpoint = NA to show the full spectrum of the color palette.
#create spatial weights for neighbour listsr.id<-attr(NYsf,"region.id")lw <-nb2listw(NY.nb,zero.policy =TRUE) #W=row standardised
In this example, the Moran’s I test suggest that the null test can be rejected. This implies random distribution of stroke across the regions of Denmark.
#globaltest spatial autocorrelation using Moran I test from spdepgm<-moran.test(NYsf$SMR,listw = lw , na.action = na.omit, zero.policy = T)gm
Moran I test under randomisation
data: NYsf$SMR
weights: lw n reduced by no-neighbour observations
Moran I statistic standard deviate = 0.12086, p-value = 0.4519
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
-0.31010080 -0.33333333 0.03694814
There’s no evidence of spatial autocorrelation at local level. Note that this data is too small and may not be the ideal to evaluate local Moran’s.
#local test of autocorrelationlm<-localmoran(NYsf$SMR,listw =nb2listw(NY.nb, zero.policy =TRUE, style ="C") , na.action = na.omit, zero.policy = T)lm
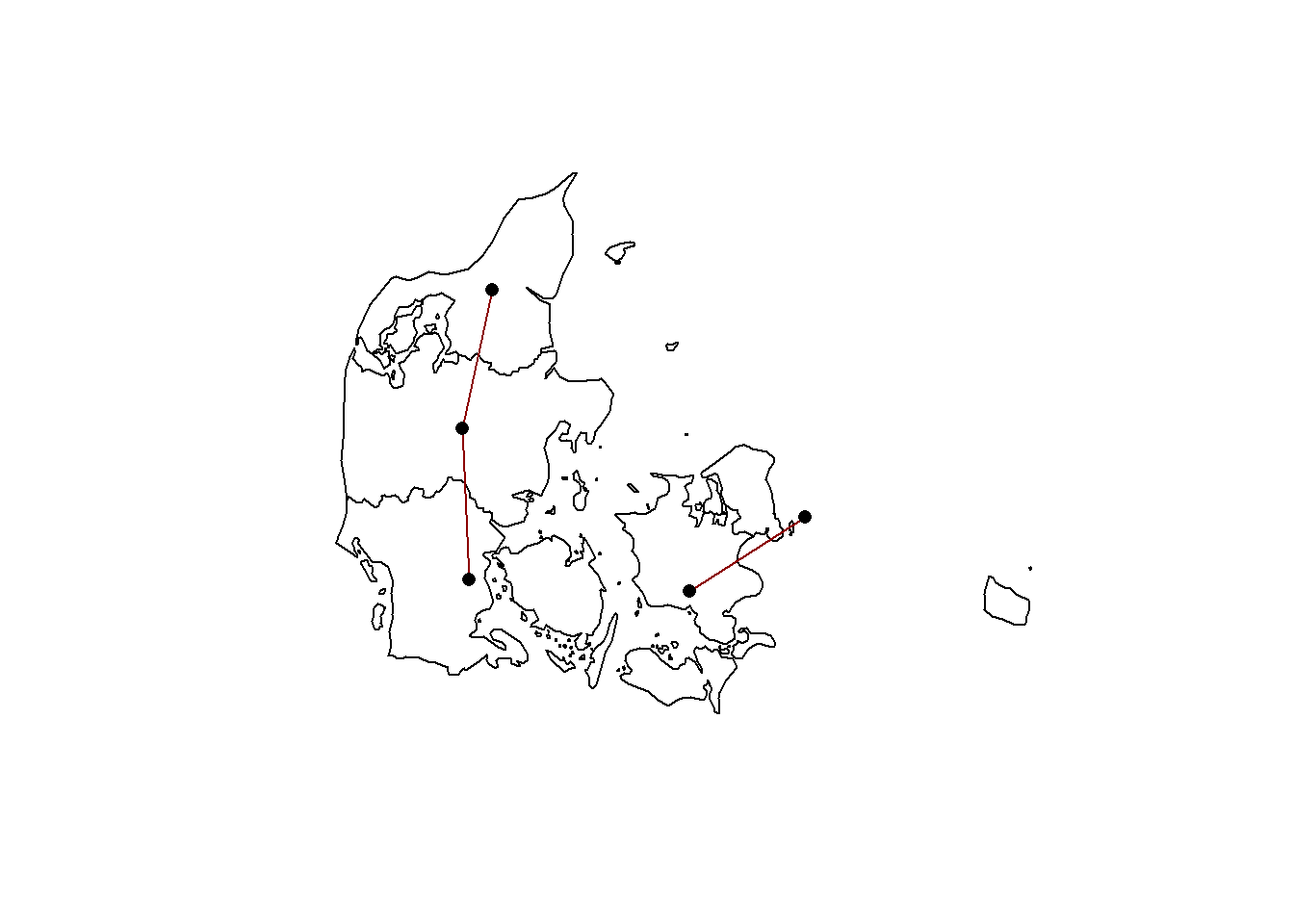
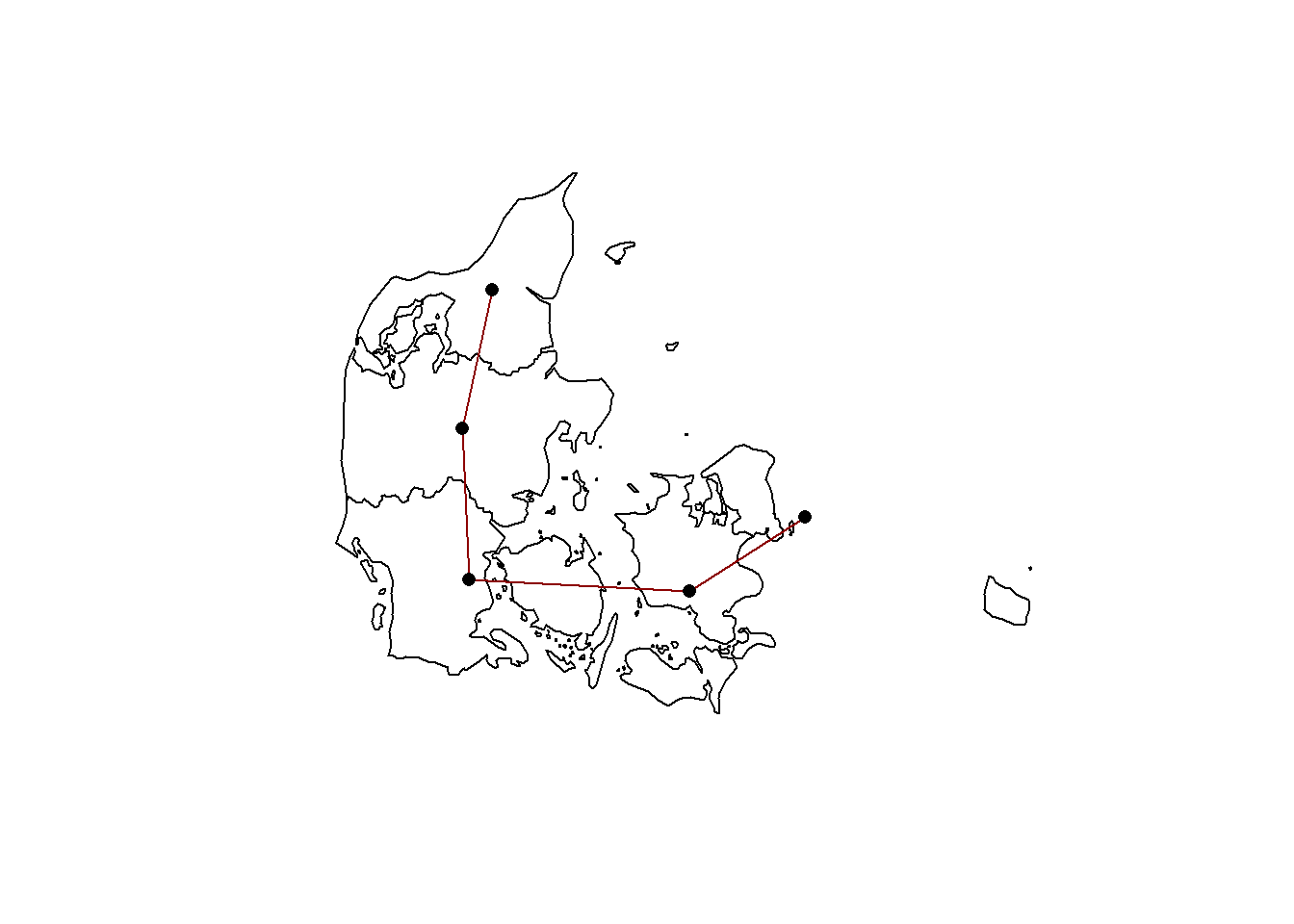
Now we plot the neighborhood weight to see if the Zealand island is linked to Jutland peninsula. The data is in the .nb file. It looks like we may need to recalculate the neighborhood as there are bridges between Zealand and Zealand. This is different situation from Staten Island and the other boroughs of New York.
library(spdep)#contiguity based neighbourhoodDKnut2.nb<-poly2nb(DKnuts2_sf2) DKnut2.nb
Neighbour list object:
Number of regions: 5
Number of nonzero links: 6
Percentage nonzero weights: 24
Average number of links: 1.2
is.symmetric.nb(DKnut2.nb)
[1] TRUE
Plotting in base R with sf object requires extracting the geometry and coordinates. Need to modify the link between Zealand and Jutland.
#create spatial weights for neighbour listsr.id<-attr(DKnuts2_sf2,"id")lw <-nb2listw(DKnut2_connected.nb,zero.policy =TRUE) #W=row standardised
Perform robust regression
#robust linear modelsDKnuts2_sf2$resids <- MASS::rlm(SMR~maleper,data=DKnuts2_sf2)$res#tmap robust linear model-residual#plot using color blind argumenttm_shape(DKnuts2_sf2) +tm_polygons(col='resids',title='Residuals')+tm_style("col_blind")
Variable(s) "resids" contains positive and negative values, so midpoint is set to 0. Set midpoint = NA to show the full spectrum of the color palette.
Check for spatial autocorrelation using Moran I test.
#globaltest spatial autocorrelation using Moran I test from spdepgm<-moran.test(DKnuts2_sf2$SMR,listw = lw , na.action = na.omit, zero.policy = T)gm
Moran I test under randomisation
data: DKnuts2_sf2$SMR
weights: lw
Moran I statistic standard deviate = -0.98413, p-value = 0.8375
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
-0.7354200 -0.2500000 0.2432931
Local test of autocorrelation
#local test of autocorrelationlm<-localmoran(DKnuts2_sf2$SMR,listw =nb2listw(DKnut2_connected.nb, zero.policy =TRUE, style ="C") , na.action = na.omit, zero.policy = T)lm
Call:lagsarlm(formula = SMR ~ maleper, data = DKnuts2_sf2, listw = lw,
type = "lag", method = "spam", zero.policy = T)
Residuals:
Min 1Q Median 3Q Max
-0.0443592 -0.0341796 0.0030004 0.0291800 0.0463583
Type: lag
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.17355 1.60916 1.9722 0.04859
maleper -0.66296 0.80039 -0.8283 0.40750
Rho: -0.78891, LR test value: 3.8347, p-value: 0.050202
Asymptotic standard error: 0.15282
z-value: -5.1625, p-value: 2.4366e-07
Wald statistic: 26.652, p-value: 2.4366e-07
Log likelihood: 8.312303 for lag model
ML residual variance (sigma squared): 0.0012291, (sigma: 0.035059)
Nagelkerke pseudo-R-squared: 0.6942
Number of observations: 5
Number of parameters estimated: 4
AIC: -8.6246, (AIC for lm: -6.7899)
LM test for residual autocorrelation
test value: 1.3631, p-value: 0.24301
Call:sacsarlm(formula = SMR ~ maleper, data = DKnuts2_sf2, listw = lw,
type = "sac", method = "MC", zero.policy = T)
Residuals:
Min 1Q Median 3Q Max
-0.034569 -0.028384 -0.004774 0.033291 0.034436
Type: sac
Coefficients: (numerical Hessian approximate standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.475165 1.583042 0.9319 0.3514
maleper 0.099753 0.817024 0.1221 0.9028
Rho: -0.62625
Approximate (numerical Hessian) standard error: 0.31056
z-value: -2.0165, p-value: 0.043744
Lambda: -0.60661
Approximate (numerical Hessian) standard error: 0.41076
z-value: -1.4768, p-value: 0.13973
LR test value: 3.9764, p-value: 0.13694
Log likelihood: 8.383149 for sac model
ML residual variance (sigma squared): 0.00086351, (sigma: 0.029386)
Nagelkerke pseudo-R-squared: 0.70274
Number of observations: 5
Number of parameters estimated: 5
AIC: -6.7663, (AIC for lm: -6.7899)
spatial filtering
#function from spatialreg#Set ExactEV=TRUE to use exact expectations and variances rather than the expectation and variance of Moran's I from the previous iteration, default FALSEDKFilt<-SpatialFiltering(SMR~maleper, data=DKnuts2_sf2,nb=DKnut2_connected.nb,#ExactEV = TRUE,zero.policy =TRUE,style="W")
An inversion has been detected. The procedure will terminate now.
It is suggested to use the exact expectation and variance of Moran's I
by setting the option ExactEV to TRUE.
14.4.3 INLA
This section uses Bayesian modeling for regression with fitting of the model by Integrated Nested Lapace Approximation (INLA). https://www.r-bloggers.com/spatial-data-analysis-with-inla/. For those wanting to analyse leukemia in New York instead of COVID-19, the dataset NY8 is available from DClusterm. INLA approximates the posterior distribution as latent Gaussian Markov random field. In this baseline analysis, the poisson model is performed without any random effect terms.
library(INLA)nb2INLA("DKnut2.graph", DKnut2_connected.nb)#This create a file called ``LDN-INLA.adj'' with the graph for INLADK.adj <-paste(getwd(),"/DK.graph",sep="")#Poisson model with no random latent effect-ideal baseline modelm1<-inla(SMR~1+maleper, data=DKnuts2_sf2, family="poisson",E=DKnuts2_sf2$Expected,control.predictor =list(compute =TRUE),control.compute =list(dic =TRUE, waic =TRUE), verbose = T )R1<-summary(m1)
In this next analysis, the Poisson model was repeated with random effect terms. This step was facilitated by adding the index term.
#Poisson model with random effect #index to identify random effect IDDKnuts2_sf2$ID <-1:nrow(DKnuts2_sf2)m2<-inla(SMR~1+ maleper +f(ID, model ="iid"), data=DKnuts2_sf2, family="poisson",E=DKnuts2_sf2$Expected,control.predictor =list(compute =TRUE),control.compute =list(dic =TRUE, waic =TRUE))R2<-summary(m2)
Plot SMR
DKnut2_sf2$FIXED.EFF <- m1$summary.fitted[, "mean"]DKnut2_sf2$IID.EFF <- m2$summary.fitted[, "mean"]#plot regression on maptSMR<-tm_shape(DKnuts2_sf2)+tm_polygons("SMR")
This next paragraph involves the use of spatial random effects in regression models. Examples include conditional autoregressive (CAR) and intrinsic CAR (ICAR).
# Create sparse adjacency matrixDK.mat <-as(nb2mat(DKnut2_connected.nb, style ="B",zero.policy =TRUE),"Matrix") #S=variance stabilise# Fit modelm.icar <-inla(SMR ~1+maleper+f(ID, model ="besag", graph = DK.mat),data = DKnuts2_sf2, E = DKnuts2_sf2$Expected, family ="poisson",control.predictor =list(compute =TRUE),control.compute =list(dic =TRUE, waic =TRUE))R3<-summary(m.icar)
The Besag-York-Mollie (BYM) now accounts for spatial dependency of neighbours. It includes random effect from ICA and index.
m.bym =inla(SMR ~-1+ maleper+f(ID, model ="bym", graph = DK.mat),data = DKnuts2_sf2, E = DKnuts2_sf2$Expected, family ="poisson",control.predictor =list(compute =TRUE),control.compute =list(dic =TRUE, waic =TRUE))R4<-summary(m.bym)
Warning: package 'brms' was built under R version 4.3.3
Loading required package: Rcpp
Loading 'brms' package (version 2.22.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').
Attaching package: 'brms'
The following object is masked from 'package:dismo':
kfold
The following object is masked from 'package:stats':
ar
#S=variance stabilise# Fit model#brm.lag<- brm (COVIDdeathraw ~ 1+Age65raw+Income+sar(NY.nb, type = "lag"),# data = DKnut2_sf2, data2 = list(NY.nb = NY.nb),# chains = 2, cores = 2)
14.5 Machine learning in spatial analysis
Up until now we have used frequentist and Bayesian spatial regression methods. Spatial data can also be analysed using machine learning such as random forest and xgboost. XGBoost estimates similar spatial effects as those in SLM and MGWR models.
library(xgboost)
Attaching package: 'xgboost'
The following object is masked from 'package:dplyr':
slice
library(tidyverse)library(shapviz)
Warning: package 'shapviz' was built under R version 4.3.3
Spatio-temporal regression combines a spatial model with a temporal model. In many cases of low disease incidence in each region it may not be possible to identify any temporal trend at a regional level.